 An
amazing thing: Popular culture is fond of hyperbole: This
or that thing is ‘amazing’, ‘brilliant’ (in the UK), or ‘incredible’,
when in truth the thing is often neither remarkable nor
surprising. However, it is
not an exaggeration to say that the AlphaGo story is amazing
and even ‘awesome’. In March 2016 AlphaGo defeated South
Korean Go professional Lee
Sedol, the strongest human player of the game.
That part of the story is told in a 90-minute documentary, AlphaGo - The Movie. But, the
story does not end there! The team that developed AlphaGo continued to explore ways
in which the methodology could be strengthened, and in doing so
produced a new version appropriately named AlphaGo Zero. The new version had zero reliance on
human knowledge of the game. Through self-teaching only,
AlphaGo Zero discovered novel strategies, concepts or plays that had
not
been seen before in the deep history of Go. In a test match it
defeated the original AlphaGo program 100 games to 0.1
An
amazing thing: Popular culture is fond of hyperbole: This
or that thing is ‘amazing’, ‘brilliant’ (in the UK), or ‘incredible’,
when in truth the thing is often neither remarkable nor
surprising. However, it is
not an exaggeration to say that the AlphaGo story is amazing
and even ‘awesome’. In March 2016 AlphaGo defeated South
Korean Go professional Lee
Sedol, the strongest human player of the game.
That part of the story is told in a 90-minute documentary, AlphaGo - The Movie. But, the
story does not end there! The team that developed AlphaGo continued to explore ways
in which the methodology could be strengthened, and in doing so
produced a new version appropriately named AlphaGo Zero. The new version had zero reliance on
human knowledge of the game. Through self-teaching only,
AlphaGo Zero discovered novel strategies, concepts or plays that had
not
been seen before in the deep history of Go. In a test match it
defeated the original AlphaGo program 100 games to 0.1
 Learning
in birds and humans: About
a century ago psychologists and neurophysiologists began to
speculate about how humans and animals learn.2
At first the focus was on
external features of the process, the thing to be learned and the
response of the learner. As so-called ‘stimulus-response’
theories
matured they gave rise to further speculation as to
possible underlying mechanisms.
Learning
in birds and humans: About
a century ago psychologists and neurophysiologists began to
speculate about how humans and animals learn.2
At first the focus was on
external features of the process, the thing to be learned and the
response of the learner. As so-called ‘stimulus-response’
theories
matured they gave rise to further speculation as to
possible underlying mechanisms.

 Initializing
a neural network: The
first step in neural network programming is to construct a network, or
specifically to define the architecture of the network to be
trained. The working part of the network (between inputs and outputs)
consists of interconnected layers of neurons. See, for example, the
‘dense’ neural network depicted in the training cycle diagram below.
That network (or the segment reproduced) consists of 3 layers of 8
neurons per layer. Straight lines represent connections.
Biases are not shown, but each neuron (circle) should be assumed to
have an
associated bias and an output activation function, also not shown..
Initializing
a neural network: The
first step in neural network programming is to construct a network, or
specifically to define the architecture of the network to be
trained. The working part of the network (between inputs and outputs)
consists of interconnected layers of neurons. See, for example, the
‘dense’ neural network depicted in the training cycle diagram below.
That network (or the segment reproduced) consists of 3 layers of 8
neurons per layer. Straight lines represent connections.
Biases are not shown, but each neuron (circle) should be assumed to
have an
associated bias and an output activation function, also not shown..

 Forward
Propagation: In a perversely reductionist sense, the
simplest possible network (the ‘null’ network) would consist of input
and output only, with no middle or ‘hidden’ layers. Forward propagation
would perform a simple linear transformation of the input, up to
activation.
Output activation might do nothing (identity function), or might
convert the transformed input to ‘0’ or ‘1’ (a step function), or could
activate the result in other ways. Realistically, though, any sort of
functional neural network would need to include at least one hidden
layer between input and output. As it happens, forward propagation is
the same across the entire network. Activated outputs of each layer
serve as inputs to the following layer, same as in the null network example. Within a layer, each neuron’s
inputs are multiplied by the corresponding weights and these products
are summed. After adding bias, the output is passed through
the activation function. This activated output serves as an input to
the next layer.
Forward
Propagation: In a perversely reductionist sense, the
simplest possible network (the ‘null’ network) would consist of input
and output only, with no middle or ‘hidden’ layers. Forward propagation
would perform a simple linear transformation of the input, up to
activation.
Output activation might do nothing (identity function), or might
convert the transformed input to ‘0’ or ‘1’ (a step function), or could
activate the result in other ways. Realistically, though, any sort of
functional neural network would need to include at least one hidden
layer between input and output. As it happens, forward propagation is
the same across the entire network. Activated outputs of each layer
serve as inputs to the following layer, same as in the null network example. Within a layer, each neuron’s
inputs are multiplied by the corresponding weights and these products
are summed. After adding bias, the output is passed through
the activation function. This activated output serves as an input to
the next layer.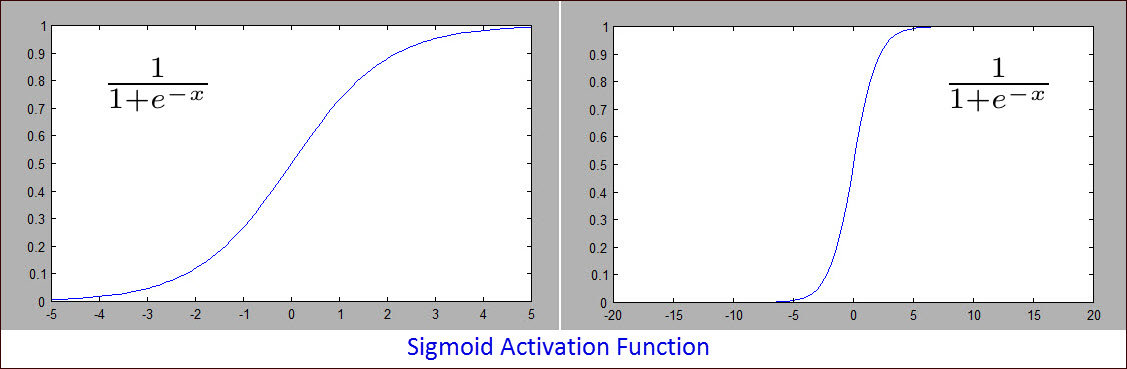




 to 0. Training consisted of repeating many
training cycles. In each cycle a randomly selected game configuration
was presented as input. The network ‘guessed’ whether the pattern was a
win or a loss for the player on move—the forward propagation part.
After each such guess, feedback was propagated from the loss function
backwards through the network. After back propagation was complete,
neuron weights and biases were updated, and the cycle repeated with
another randomly selected input. In the training report
(right) the third parameter ‘0’ refers to an input
transform that was not used in this specific exercise. The last
parameter ‘.01’ is the criterion
for correct classification. The value .01 means that to be counted as
‘1’ (win)
the sigmoid activated output must be > 0.99. Similarly, to count
as classifying a loss the activated output must be < 0.01. This
value is not a probability, but can be thought of in a similar way.
to 0. Training consisted of repeating many
training cycles. In each cycle a randomly selected game configuration
was presented as input. The network ‘guessed’ whether the pattern was a
win or a loss for the player on move—the forward propagation part.
After each such guess, feedback was propagated from the loss function
backwards through the network. After back propagation was complete,
neuron weights and biases were updated, and the cycle repeated with
another randomly selected input. In the training report
(right) the third parameter ‘0’ refers to an input
transform that was not used in this specific exercise. The last
parameter ‘.01’ is the criterion
for correct classification. The value .01 means that to be counted as
‘1’ (win)
the sigmoid activated output must be > 0.99. Similarly, to count
as classifying a loss the activated output must be < 0.01. This
value is not a probability, but can be thought of in a similar way.
How to play: In the vertical bar to the right of the group you wish to reduce, indicate the number of stones to leave (not the number to remove). Then click Enter Play.
After each of your plays, click Computer to display the computers reply.
At the beginning of the game, you may click Computer to allow the computer to play first.