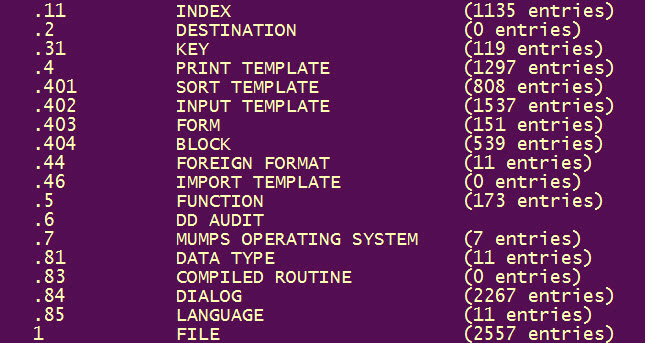
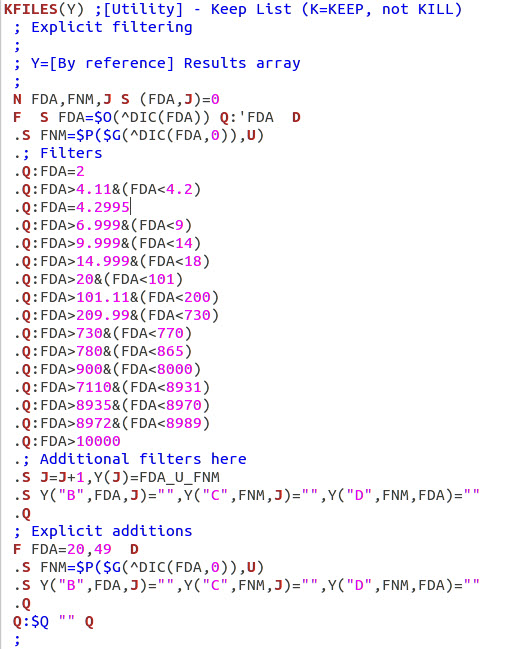
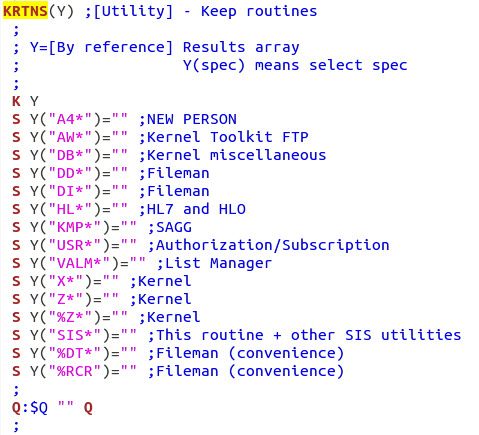
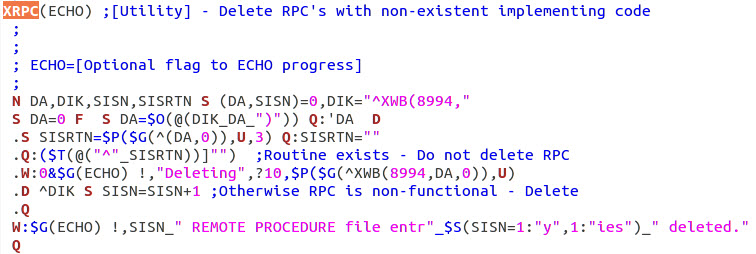
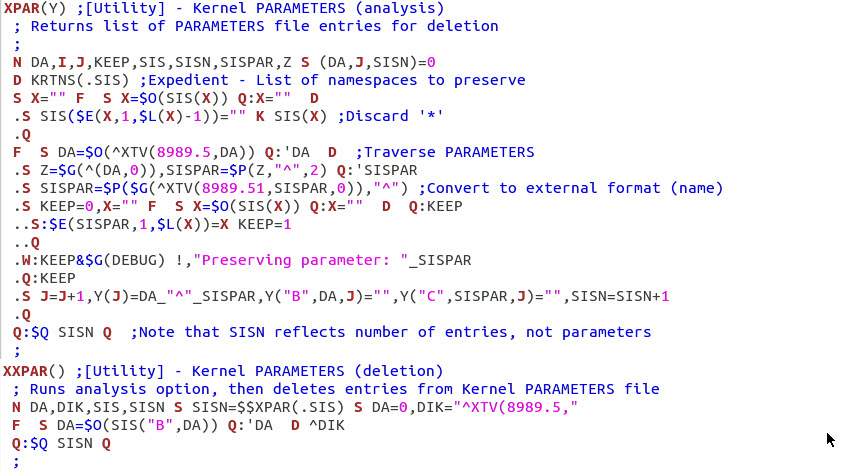
| Step 1 - Identify files to delete or preserve (include
associated templates and forms). After deletion, remove empty globals. |
| Step 2 - Identify routines to delete or
preserve. After deletion, remove ROUTINE file entry. |
| Step 3 - Remove remote procedures that refer to
non-existent routines. |
| Step 4 - Remove options that refer to non-existent
routines. Then remove references to non-existent options,
etc. (recursively). |
| Step 5 - Repeat step 4 for options that refer to
non-existent files. |
| Step 6 - Remove unwanted protocols by application
namespace.. |
| Step 7 - Identify parameter definitions to delete or
preserve.
Remove unwanted Kernel parameters and parameter definitions. |
| Step 8 - Miscellaneous cleanup. Zero-out the
AUDIT file. |

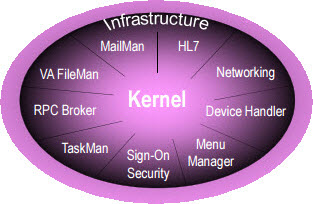 A
collection of special applications reside at the heart of VistA.
These uniquely important components provide common services
to
VistA applications, including, communication services, user
and programmer interfaces to the MUMPS database, security services,
task scheduling and other system management functions, as
well as
programming and application sharing tools. This
infrastructure
called the
A
collection of special applications reside at the heart of VistA.
These uniquely important components provide common services
to
VistA applications, including, communication services, user
and programmer interfaces to the MUMPS database, security services,
task scheduling and other system management functions, as
well as
programming and application sharing tools. This
infrastructure
called the